Fixed benchmark snapshot shared by the Hugging Face notebook, benchmark-only HTML build, and generated TeX includes. Snapshot label: paper-2026-02-11T1915Z. Cutoff: 2026-02-12T06:15:00+11:00.
Trained params is the average non-zero parameter count in the fitted model across folds. Avg active params / classification is the mean number of active parameters or scoring decisions touched while classifying one product.
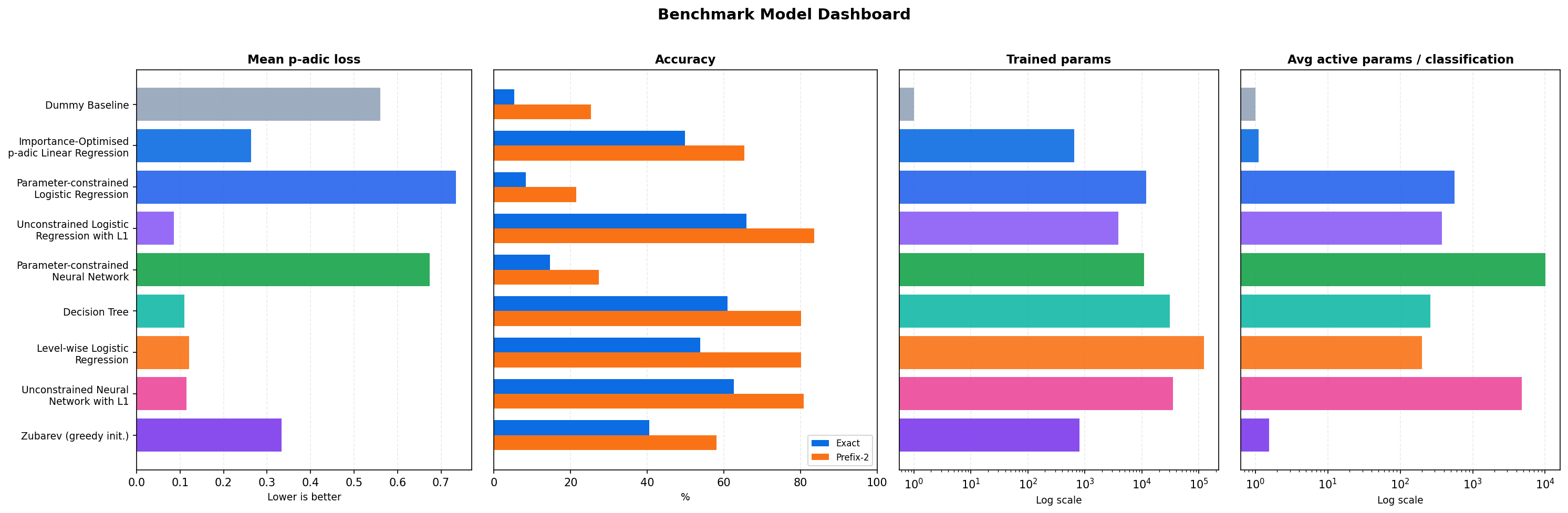
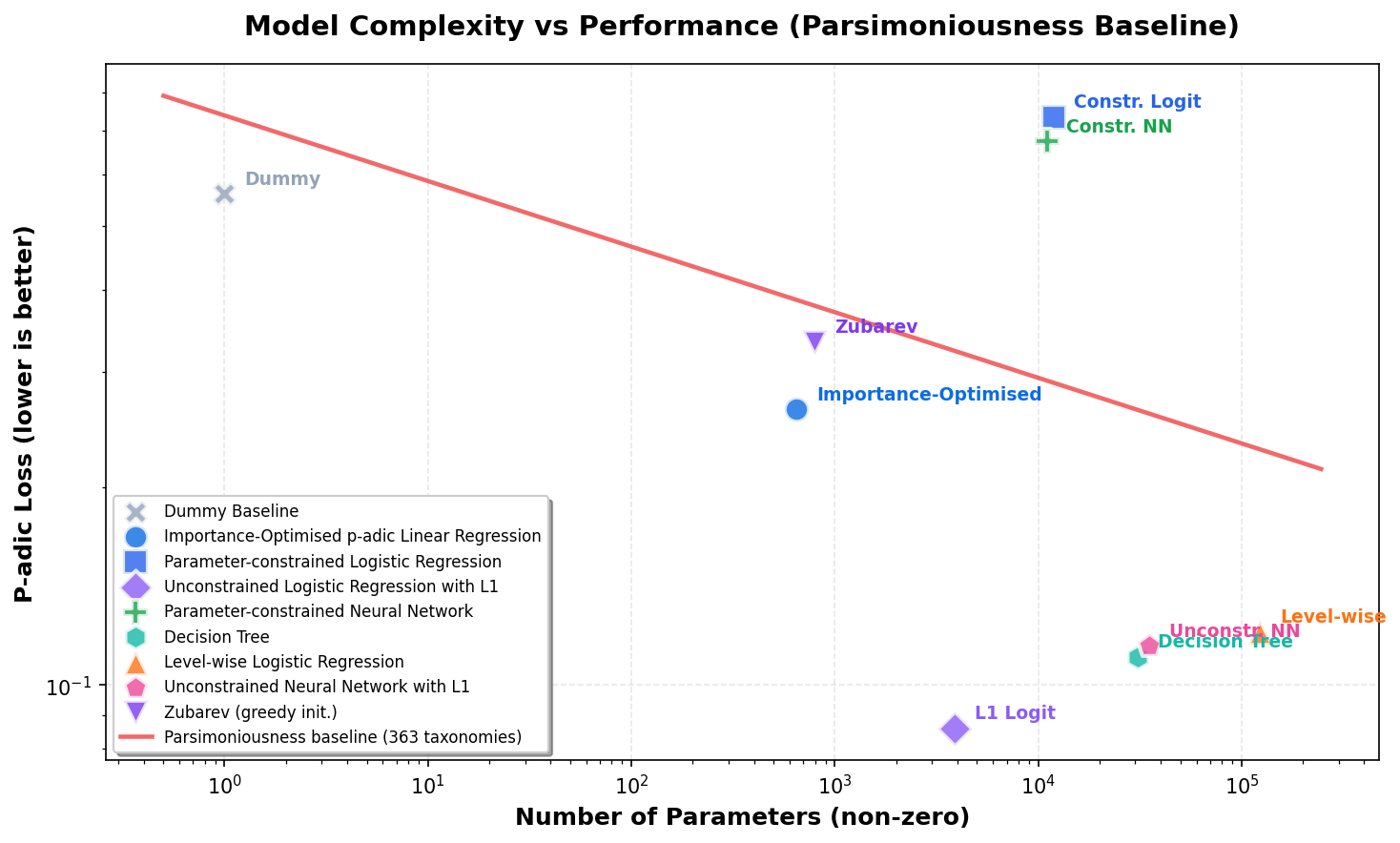
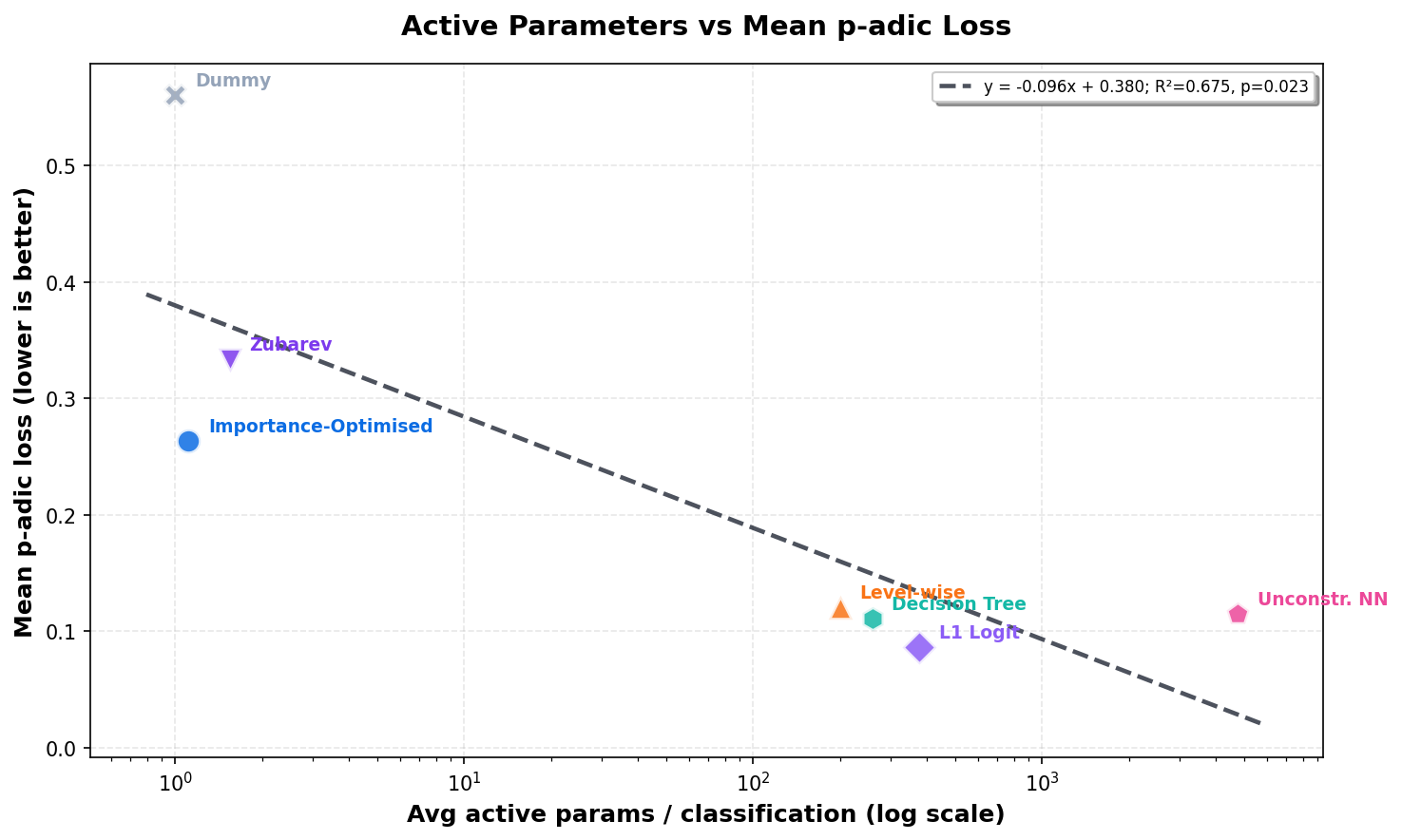
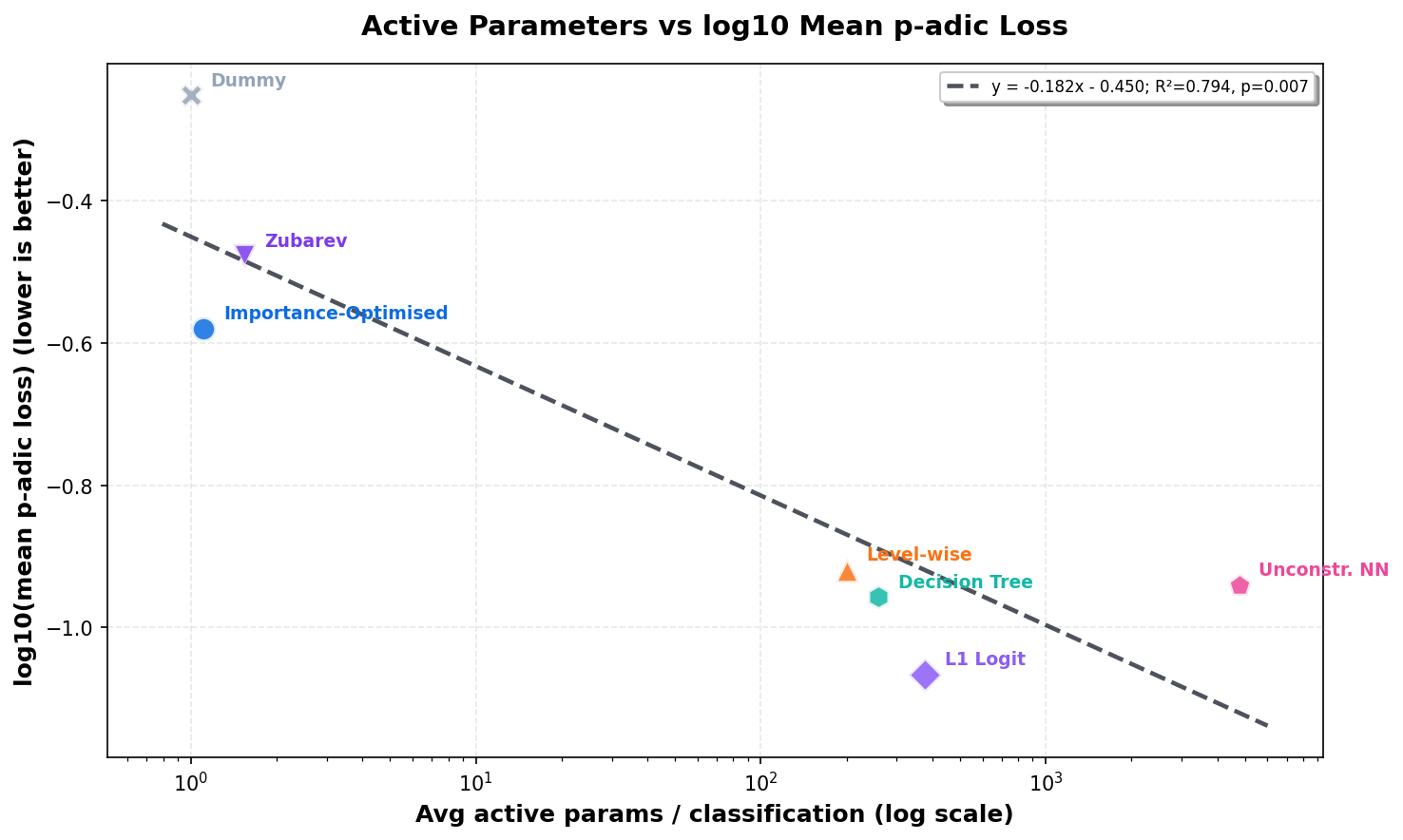
| Model | Trained params | Mean p-adic loss | Exact acc. | Prefix-2 acc. | Avg active params / classification |
|---|---|---|---|---|---|
| Dummy Baseline | 1.0 | 0.560442 | 5.32% | 25.30% | 1.00 |
| Importance-Optimised p-adic Linear Regression | 648.2 | 0.263237 | 49.82% | 65.38% | 1.11 |
| Parameter-constrained Logistic Regression | 11913.0 | 0.733943 | 8.35% | 21.52% | 560.00 |
| Unconstrained Logistic Regression with L1 | 3886.0 | 0.085839 | 65.87% | 83.51% | 375.99 |
| Parameter-constrained Neural Network | 10999.0 | 0.673437 | 14.63% | 27.33% | 10149.88 |
| Decision Tree | 30947.0 | 0.110314 | 60.93% | 80.12% | 258.35 |
| Level-wise Logistic Regression | 123174.8 | 0.120450 | 53.81% | 80.08% | 199.99 |
| Unconstrained Neural Network with L1 | 35209.0 | 0.114660 | 62.56% | 80.90% | 4766.06 |
| Zubarev (greedy init.) | 797.4 | 0.333238 | 40.49% | 58.03% | 1.54 |