Training data spans 7,678 products across
554 taxonomies.
Of 42,240 total tags in the dataset,
16,663 tags were used
(tags appearing fewer than 5 times were filtered out).
17,864 products were discarded due to missing or sparse taxonomy labels.Explore the full dataset → | View defective taxonomy labels →
Dummy Baseline
Always predicts most common taxonomy (baseline for comparison)
Dedicated `latest` and `paper` benchmark pages, including the average active parameters touched per classification for the importance-optimised p-adic linear regressor.
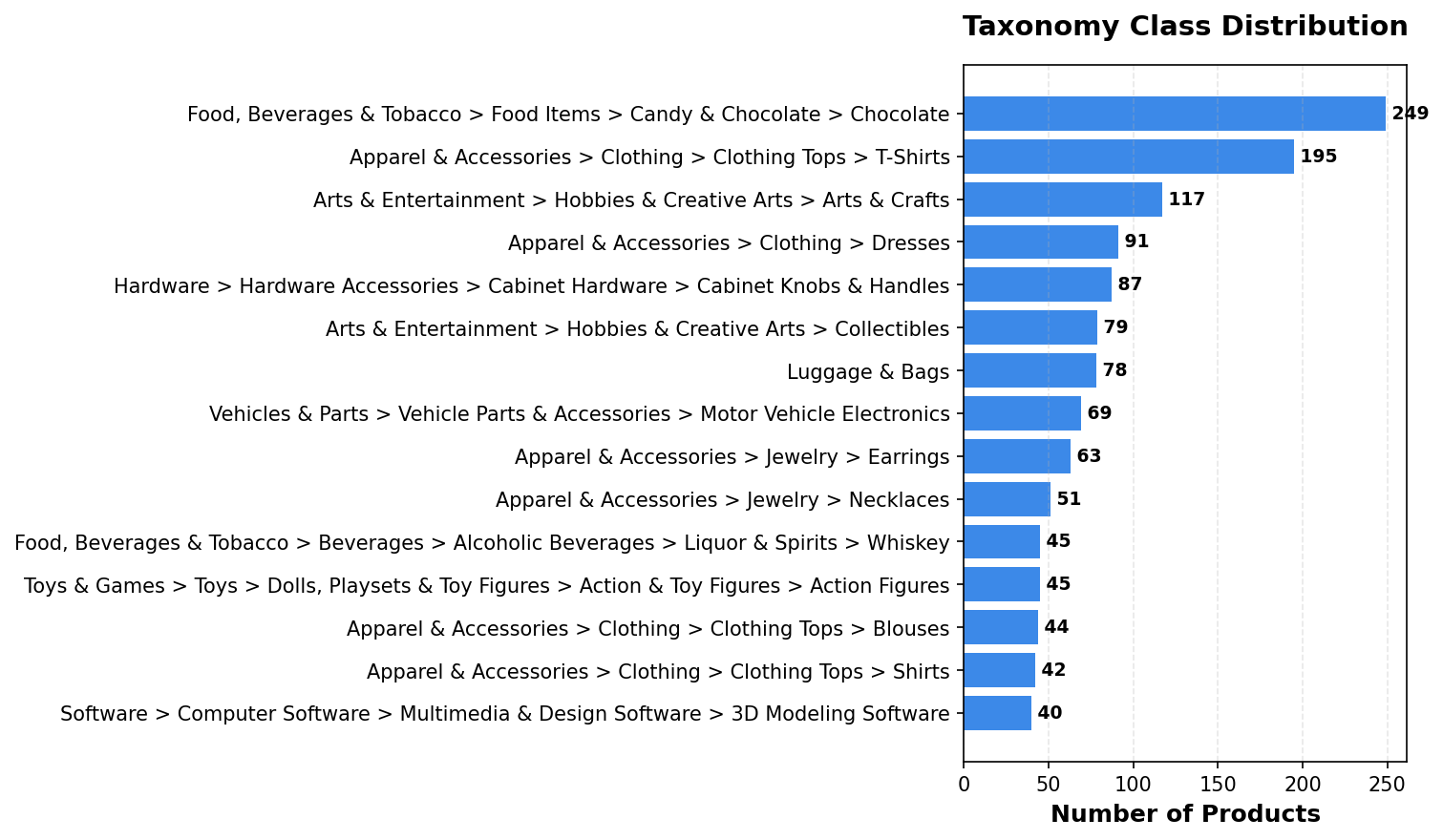
Distribution of products across the most common taxonomy classes
Top 10 taxonomy classes
Taxonomy ID
Name
Path
Samples
Share
gid://shopify/TaxonomyCategory/bt
Baby & Toddler
Baby & Toddler
257
3.3%
gid://shopify/TaxonomyCategory/lb
Luggage & Bags
Luggage & Bags
99
1.3%
gid://shopify/TaxonomyCategory/bu
Bundles
Bundles
77
1.0%
gid://shopify/TaxonomyCategory/gc
Gift Cards
Gift Cards
27
0.4%
gid://shopify/TaxonomyCategory/pa
Product Add-Ons
Product Add-Ons
27
0.4%
gid://shopify/TaxonomyCategory/os
Office Supplies
Office Supplies
21
0.3%
gid://shopify/TaxonomyCategory/na
Uncategorized
Uncategorized
19
0.2%
gid://shopify/TaxonomyCategory/sg
Sporting Goods
Sporting Goods
17
0.2%
gid://shopify/TaxonomyCategory/bi
Business & Industrial
6
16
0.2%
gid://shopify/TaxonomyCategory/el
Electronics
8
11
0.1%
Tags with strongest signal
Tag
Top taxonomy
Weight
Max |weight|
No tag signal data available
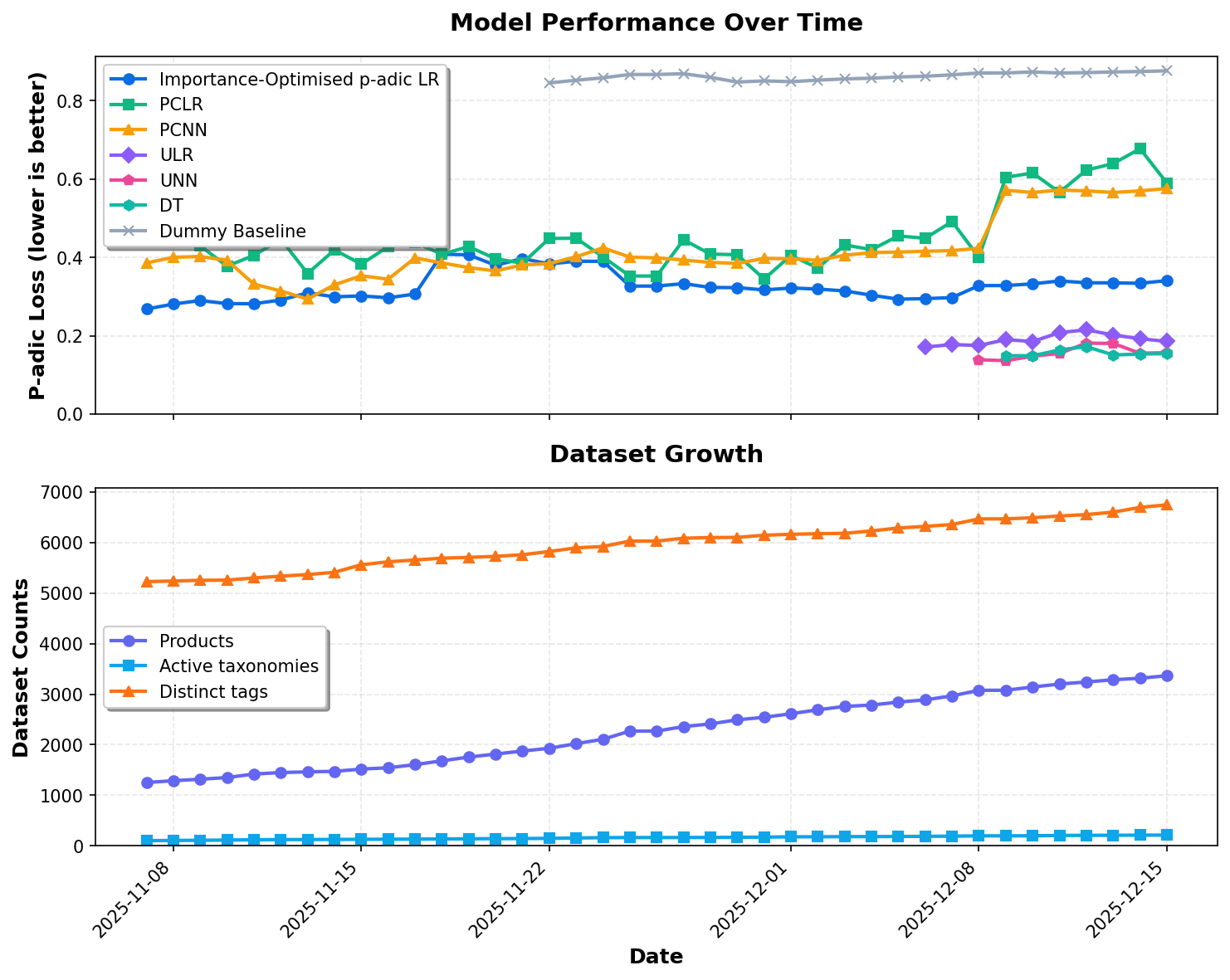
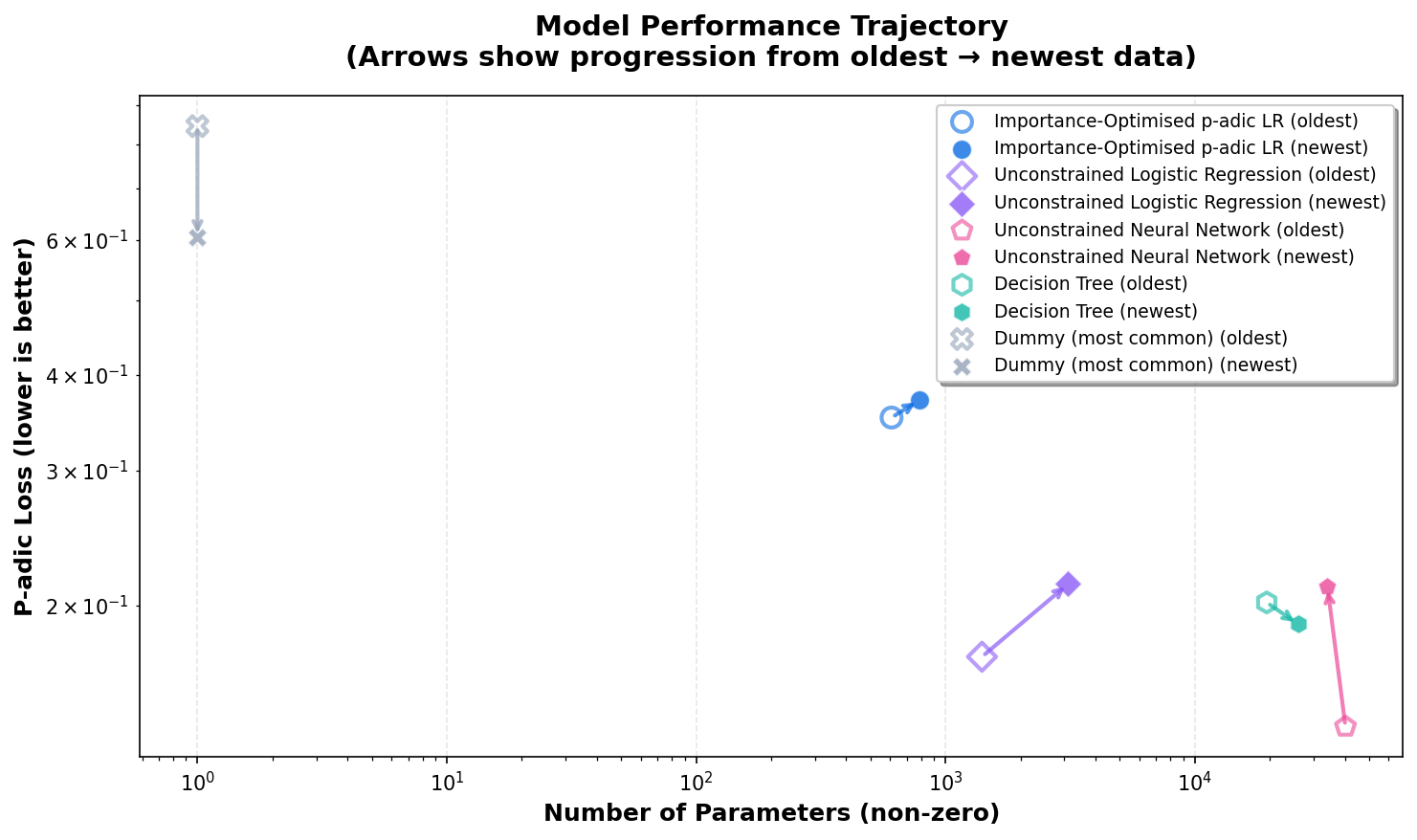
Historical Performance Trends
Tracking model performance and dataset growth over time. Lower p-adic loss indicates better predictions.
Model
Slope (per product)
Intercept
R²
p-value
Importance-Optimised p-adic LR
-0.000000
0.3490
0.0020
0.4995
PCLR
0.000022
0.5051
0.6202
6.96e-51
PCNN
0.000006
0.5395
0.0660
6.74e-05
ULR
0.000005
0.1955
0.7761
3.24e-68
UNN
0.000004
0.1776
0.4353
7.23e-27
Decision Tree
0.000003
0.1691
0.5440
4.06e-36
Zubarev (UMLLR)
0.000002
0.3930
0.3960
8.62e-23
Zubarev (zeros)
0.000007
0.3925
0.8209
1.25e-73
Zubarev (M1)
0.000001
0.4076
0.1807
6.49e-10
Zubarev (M2)
0.000001
0.4030
0.2663
1.36e-14
Dummy Baseline
-0.000017
0.8395
0.3173
8.16e-20
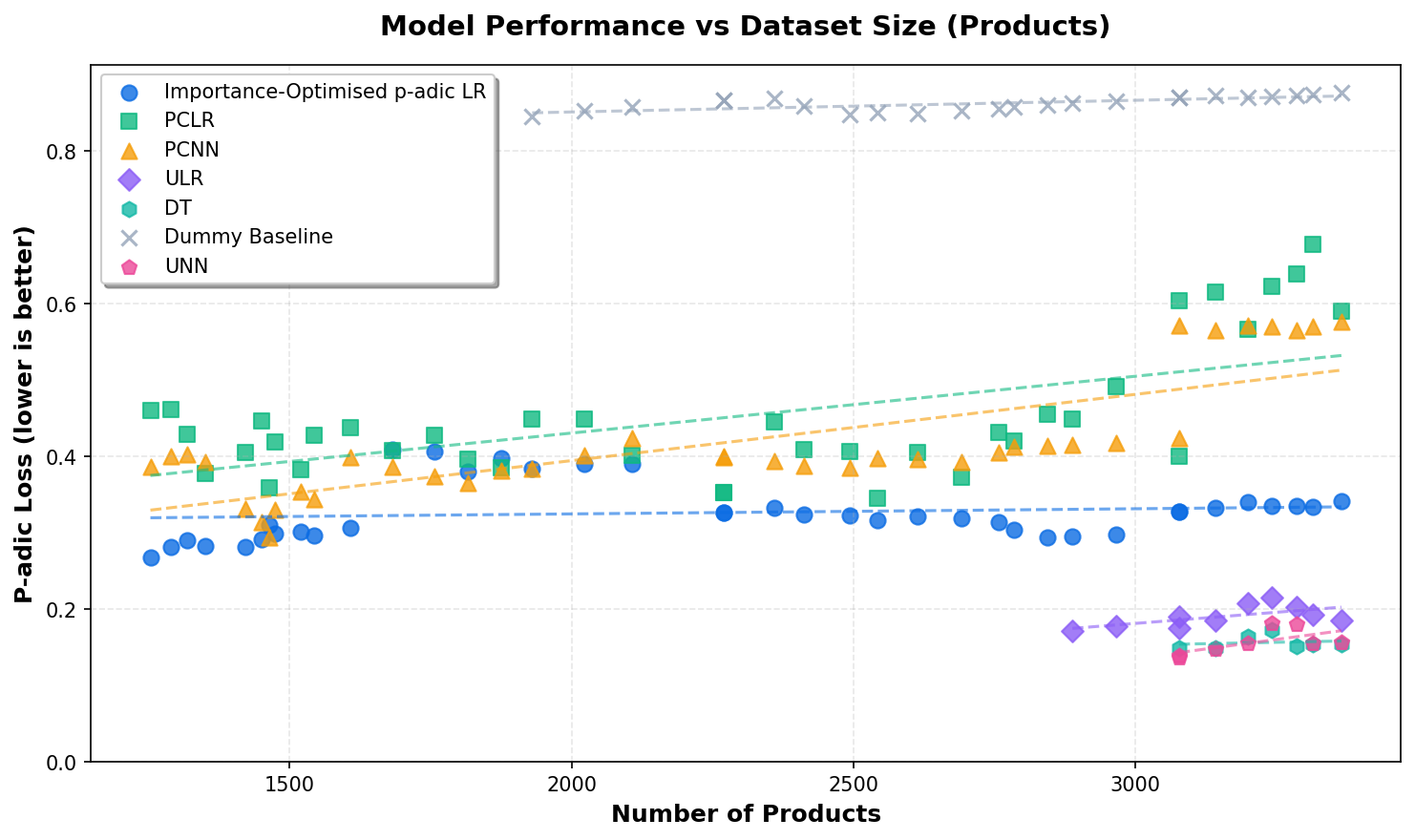
Extrapolation Analysis: When Will Importance-Optimised p-adic LR Outperform Other Models?
Based on current regression trends, we can extrapolate when Importance-Optimised p-adic LR
will achieve better performance (lower p-adic loss) than other models as the dataset grows.
The confidence intervals are calculated using bootstrap resampling (n=1000).
Statistical Notes: The crossover points are calculated by finding where the
regression lines intersect. The 95% confidence intervals are derived from bootstrap resampling
of the regression parameters. The probability estimates indicate the likelihood that the crossover
will occur given the current trends. Date predictions are based on linear extrapolation of dataset
growth and should be interpreted with caution.
Model
Slope (per tag)
Intercept
R²
p-value
Importance-Optimised p-adic LR
0.000001
0.3368
0.0132
0.0793
PCLR
0.000030
0.3683
0.6564
5.71e-56
PCNN
0.000013
0.4509
0.1761
1.93e-11
ULR
0.000006
0.1703
0.7177
6.07e-58
UNN
0.000007
0.1325
0.7015
6.17e-55
Decision Tree
0.000004
0.1473
0.5937
3.58e-41
Zubarev (UMLLR)
0.000003
0.3807
0.3517
8.13e-20
Zubarev (zeros)
0.000010
0.3457
0.8127
9.08e-72
Zubarev (M1)
0.000001
0.3996
0.2253
2.70e-12
Zubarev (M2)
0.000002
0.3932
0.2938
3.29e-16
Dummy Baseline
-0.000014
0.8460
0.1249
7.21e-08
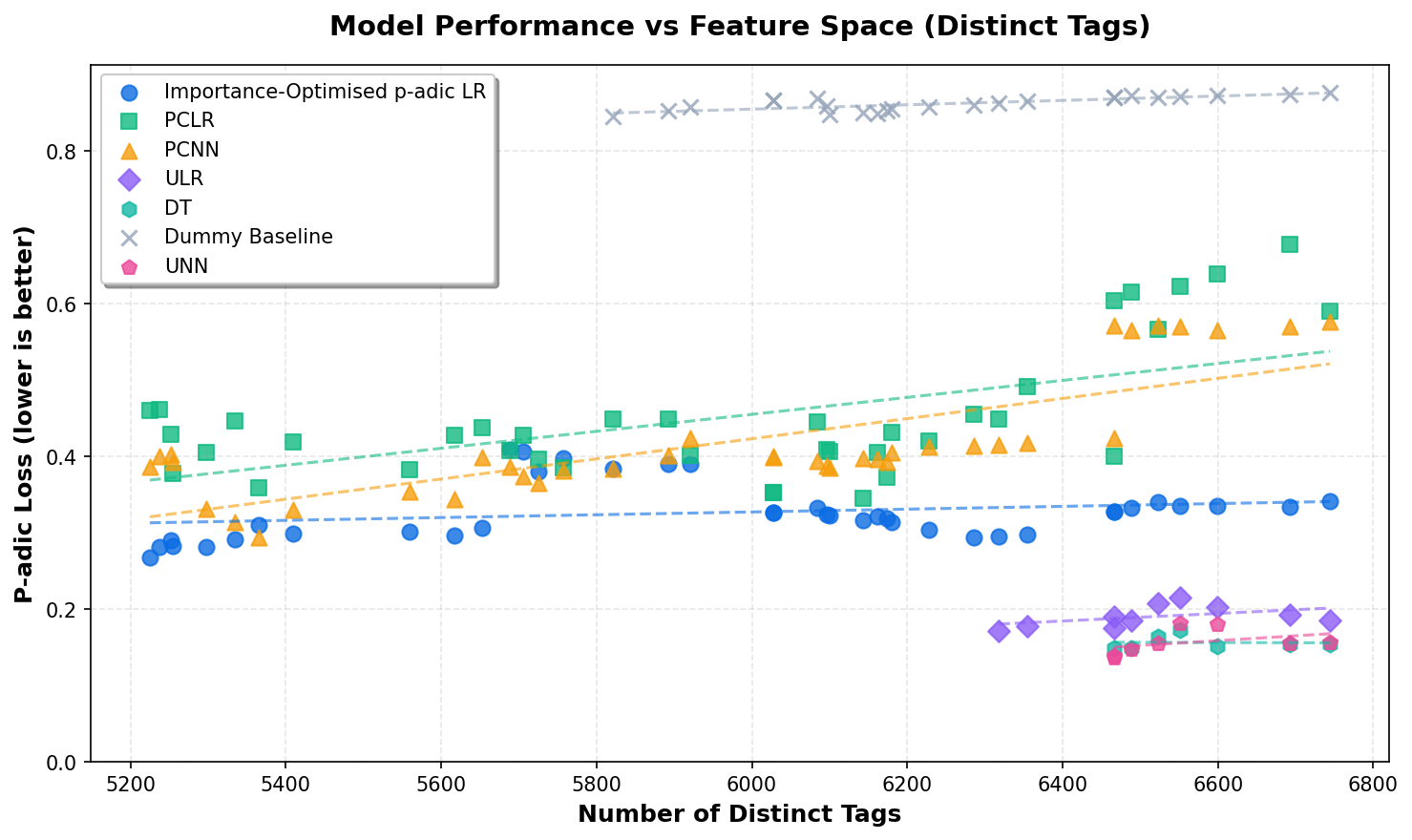
Extrapolation Analysis: When Will Importance-Optimised p-adic LR Outperform Other Models?
Based on current regression trends, we can extrapolate when Importance-Optimised p-adic LR
will achieve better performance (lower p-adic loss) than other models as the dataset grows.
The confidence intervals are calculated using bootstrap resampling (n=1000).
Statistical Notes: The crossover points are calculated by finding where the
regression lines intersect. The 95% confidence intervals are derived from bootstrap resampling
of the regression parameters. The probability estimates indicate the likelihood that the crossover
will occur given the current trends. Date predictions are based on linear extrapolation of dataset
growth and should be interpreted with caution.
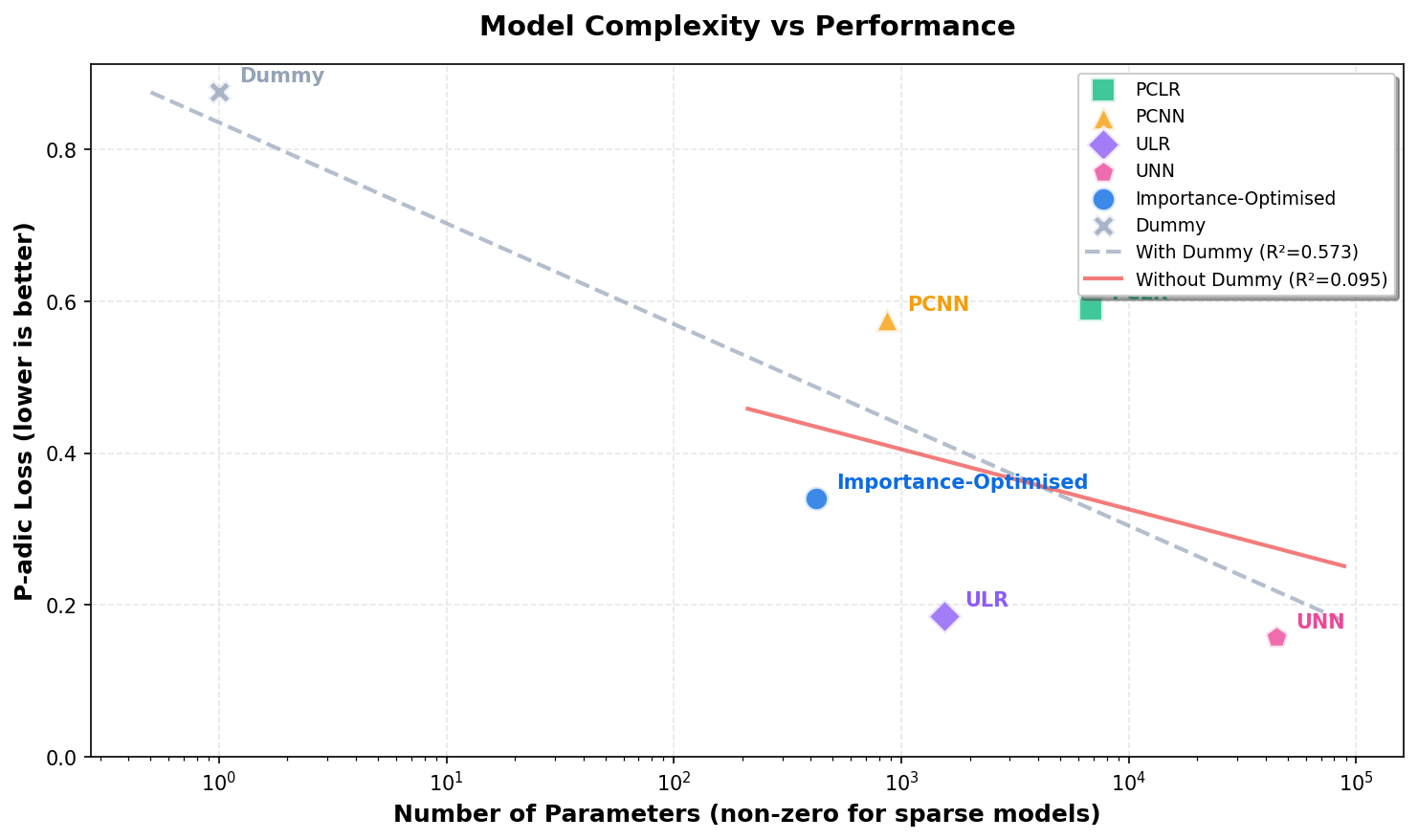
Both axes use log scale. The red line is the fixed parsimoniousness baseline rather than a fitted regression.
Why parsimony matters.
The question here is not just which model has the lowest loss, but which model gets good p-adic loss with the fewest effective parameters. That is exactly where the smaller p-adic models are interesting.
Where this baseline came from.
The original score came from a log-log regression on model size versus loss, rounded to
-0.1 × log₁₀(params) - 0.2. Looking across historical snapshots, those scores drifted as the dataset covered more taxonomies, so the current baseline adds
+ 0.3 × log₁₀(taxonomies / 1,000) to keep comparisons stable as the benchmark grows. For readability, we also re-centre the displayed score by dropping the old constant offset; that keeps the current tables mostly positive without changing the relative comparisons.
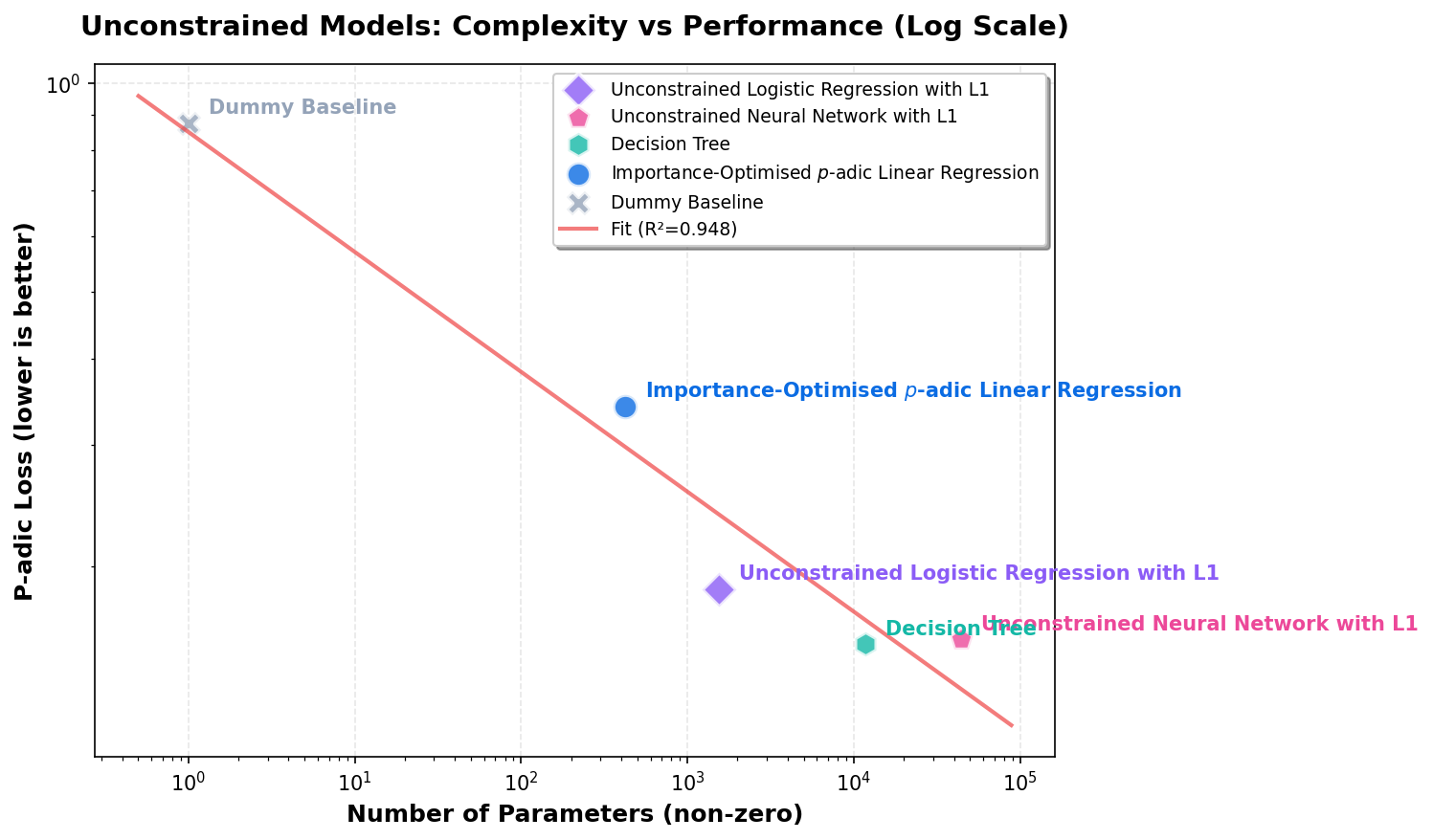
Parsimoniousness baseline: log₁₀(loss) = -0.1 × log₁₀(params) + 0.3 × log₁₀(taxonomies / 1,000) Current snapshot taxonomies: 554 Parsimony score = baseline log₁₀(loss) − observed log₁₀(loss). Positive means better than baseline.
Model
Params
Loss
log₁₀(params)
log₁₀(loss)
Baseline log₁₀(loss)
Parsimony score
Level-wise Logistic
132,415
0.1008
5.1219
-0.9966
-0.5891
+0.4075
ULR
4,473
0.2552
3.6506
-0.5931
-0.4420
+0.1511
Decision Tree
35,430
0.2195
4.5494
-0.6585
-0.5319
+0.1266
Importance-Optimised
1,011
0.3752
3.0049
-0.4258
-0.3774
+0.0483
UNN
26,382
0.2750
4.4213
-0.5606
-0.5191
+0.0416
Zubarev (M1)
2,973
0.4102
3.4732
-0.3870
-0.4243
-0.0373
Zubarev (M2)
2,978
0.4102
3.4739
-0.3870
-0.4243
-0.0374
Zubarev (UMLLR)
3,162
0.4090
3.4999
-0.3883
-0.4269
-0.0386
Dummy
1
0.9261
0.0000
-0.0334
-0.0769
-0.0436
Zubarev (zeros)
3,376
0.4696
3.5285
-0.3283
-0.4298
-0.1015
PCNN
864
0.7429
2.9365
-0.1291
-0.3706
-0.2415
PCLR
17,606
0.7817
4.2457
-0.1070
-0.5015
-0.3946
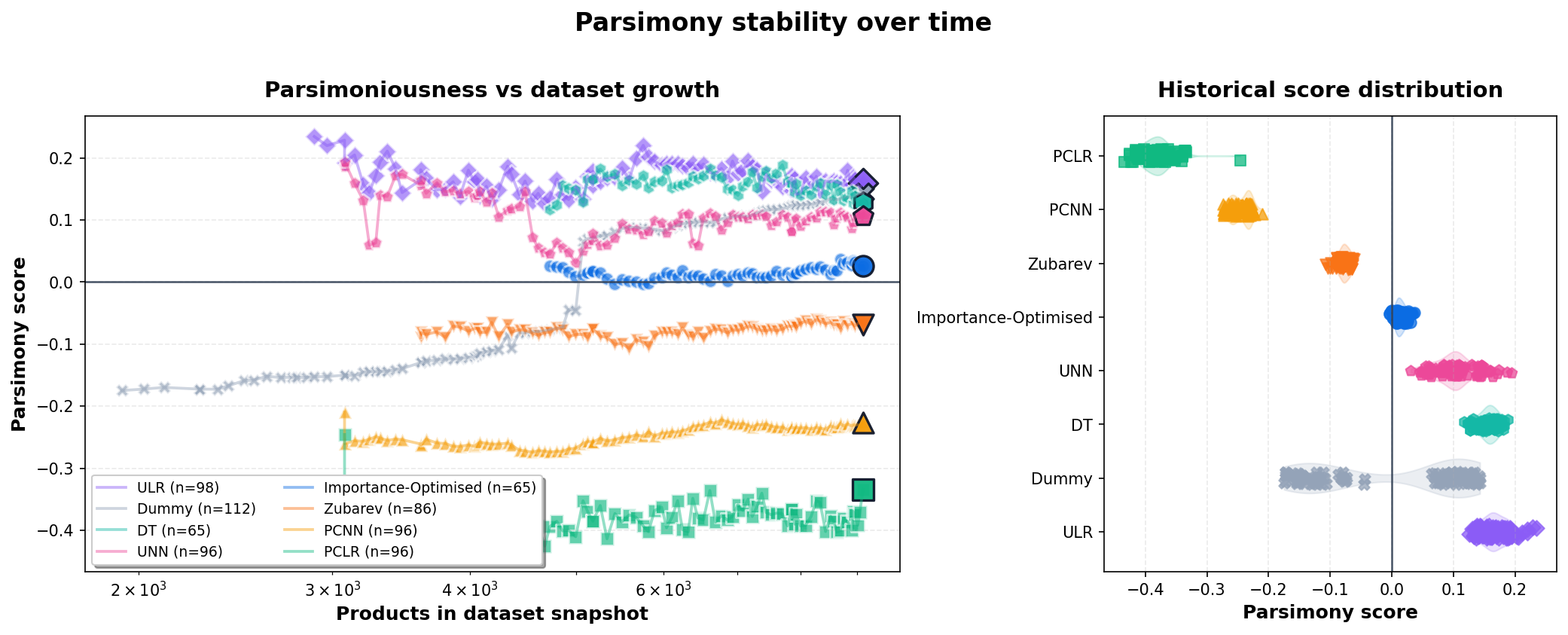
Left: parsimony score versus dataset size. Right: score distribution across historical snapshots. Positive means better than the taxonomy-adjusted baseline.
Model
Snapshots
Mean score
Std dev
Span
Latest score
Latest products
Unconstrained Logistic Regression with L1
206
+0.1642
0.0177
0.1083
+0.1516
7,690
Decision Tree
173
+0.1475
0.0184
0.0782
+0.1271
7,690
Importance-Optimised $p$-adic Linear Regression
173
+0.0690
0.0468
0.1295
+0.0488
7,690
Unconstrained Neural Network with L1
204
+0.1203
0.0333
0.1631
+0.0420
7,690
Zubarev (UMLLR init)
194
-0.0544
0.0239
0.0929
-0.0383
7,690
Dummy Baseline
220
+0.0638
0.1174
0.3436
-0.0431
7,690
PCNN
204
-0.1818
0.0730
0.1992
-0.2410
7,690
PCLR
204
-0.3781
0.0218
0.1880
-0.3941
7,690
Smaller standard deviation and span mean a model’s parsimoniousness is more stable as the dataset grows.
Unconstrained models only (no PCLR/PCNN). Both axes on log scale.